
Summary of some free LLMs APIs providers
The Issue
Hello, have you ever struggled with Google to find a place that allows free usage of large language model APIs (LLMs)? I have been like you, trying to search all over the Internet only to realize that... there is no such place. But at least I found some providers that allow trial API usage, or in other words, you can use them but with certain daily limits.
Clearly, the reality is that LLMs need sufficiently powerful hardware to serve many users. If everyone could call them freely, it would be very difficult. The purpose of the limits has its pros and cons. The good side is that it allows more people to access it, mainly serving research and personal use. However, when deploying products to end-users, a more stable and long-term solution should be sought.
Below are some providers of free APIs within limits that I have gathered, with the caveat that the limits may change in the future. Some are being applied in personal projects. Overall, they have relatively high stability, and whether the limits are comfortable or not depends on your usage purpose. As for me, it's sufficient. After all, as a free user, I shouldn't ask for more 😅. If I overuse, I can switch between services 😎. Without further ado, let's get started.
Github Models
This is a service I frequently use in personal projects. Github Models allows the use of many large language models from both open-source and proprietary sources, including gpt-5, Grok, DeepSeek... The usage limits depend on the model, with milestones like Low/High/Custom... For more details, please refer to Rate limits.
The advantages are the "breathable" limits, many advanced models, and rapid updates. The critical downside is the cut-off context, with most limited to 8000 tokens in, 4000 tokens out.
For more details, visit: Models.
OpenRouter
OpenRouter acts as a distributor of services from various providers, so they have a program for free trials of some models ending with :free. If you want to use any model, try searching for it; if it ends with :free, you can use it for free.
The advantages are that there are quite a few free models here, but there are hardly any major names like Claude, GPT... Additionally, the limits are relatively low, with only 50 requests per day. If the account has purchased at least 10 credits, the number will increase to 1000 requests.
For more details, visit: OpenRouter Pricing Plans.
Ollama Cloud
Ollama is a name that is not too unfamiliar. Many people might know it for its ability to run open-source models with just a simple command. Ollama Cloud is their latest service, allowing large language models to run in the cloud, or in other words, calling APIs to use the models.
The advantage is that with a free account, you can use some prominent models like DeepSeek 3.1, gpt-oss, qwen3-coder... with comfortable limits, as the published documentation does not specify exact usage limits, probably due to the data collection phase. The downside is that only a few open-source models are supported.
For more details, visit: Ollama Cloud.
Vercel AI
Another name that is not too unfamiliar, Vercel is a provider that allows deployment of many services like a website or API server... Vercel AI Gateway is just one of them; however, they are very "generous" by offering users $5 in free credits monthly to call APIs.
The advantage is that with $5, you can use most of the currently "hot" models, including Claude (which is very rare). The downside is that you have to add a payment method to your account.
For more details, visit: Pricing.
Cerebras
The name Cerebras has been mentioned a few times in the blog. Cerebras is one of the leading companies in providing services or hardware for the fastest token "release" speed. Some open-source models they provide can run at speeds of several thousand tokens/s. Occasionally, they post articles boasting about their servers achieving incredible token release speeds.
The advantage is the response speed, with a maximum allowed tokens per day of 1 million, along with many limits related to the frequency of calls per minute/hour. The downside is that the models are not very diverse; some notable names include gpt-oss-120b, zai-glm-4.6, and qwen-3-235b.
Readers can refer to the usage limit table below.
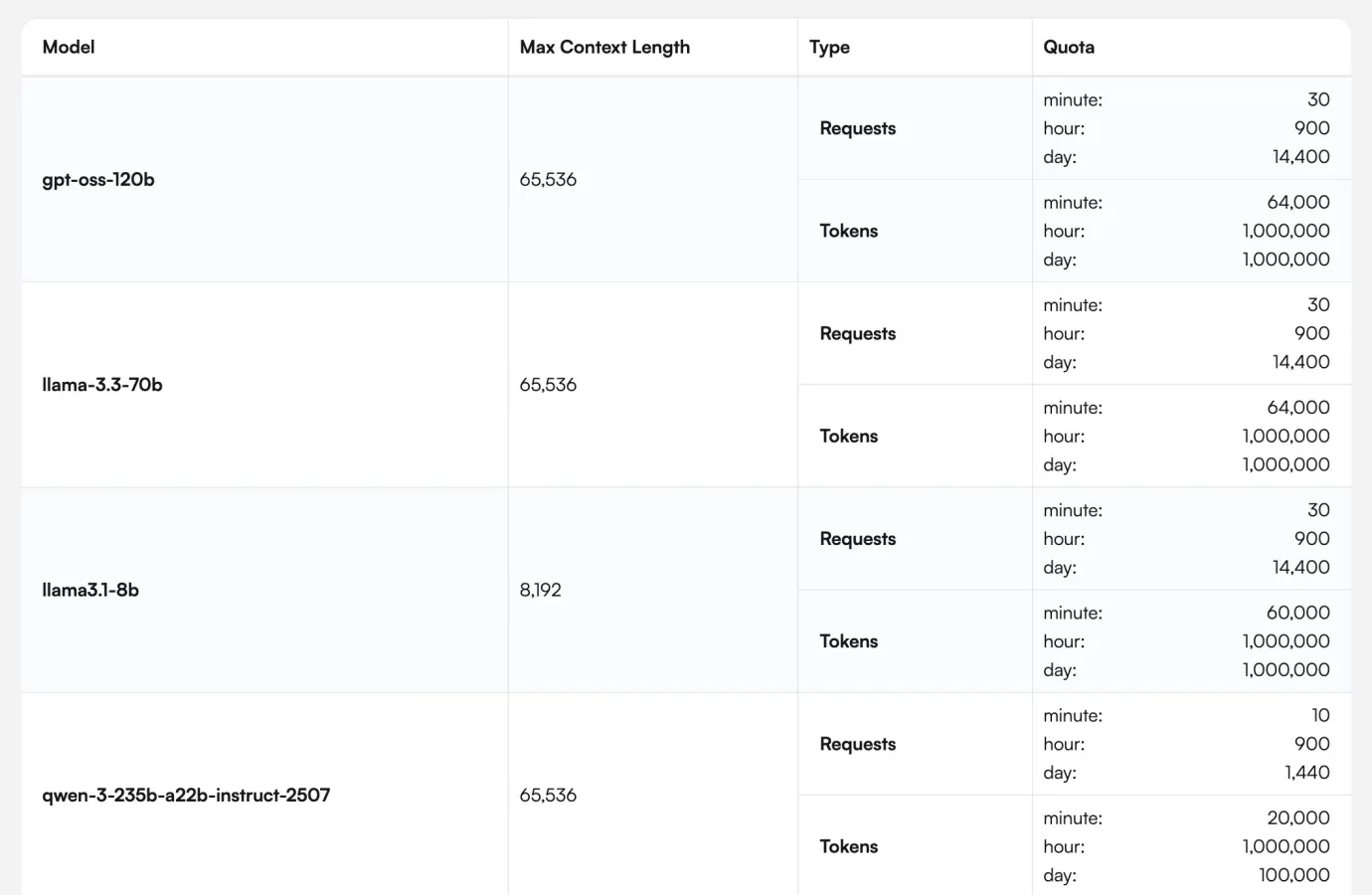
Groq
Mentioning Cerebras without mentioning Groq would indeed be a mistake. Groq, like Cerebras, is a provider of both hardware and APIs focusing on speed. Groq occasionally posts articles boasting about running models at incredible speeds.
The advantage is speed and a diverse range of open-source models. The downside is that the token limits are not very high, with models like gpt-oss-120b capped at 200K daily. However, if upgraded to Developer, the limit increases to 500K.
For more details, visit: Rate Limits.
Gemini API
A whale in the free API provision space. It is said that using it in Google AI Studio incurs no charges. If using the API, however, it is still charged as usual.
The advantage is that the free package can use most of the current models from Gemini, with limits applied based on the strength of each model. Some compact models like Gemma 3n can be used with very large limits. The downside is that there is only Gemini's models available.
For more details, visit: Standard API rate limits.
Nvidia NIM
Lastly, a prominent name is Nvidia NIM, a leading hardware provider for large language models. In addition, it offers trials for some open-source LLM models.
The advantage is that there are many open-source models available here. All limits are capped at 40 requests per minute for all models. The downside? Of course, it's the absence of the current leading names.
For more details, visit: Retrieval APIs.
Besides the names mentioned above, there are many other service providers like Cloudflare AI, Together AI, Z.ai... However, through practical experience, I find there are still many limitations, so I won’t list them in detail in this article.
What about you? Which API provider are you currently using? Or if you know more, please leave a comment below. Thank you.